I Built a Metric That Doesn't Exist: Measuring Semantic Fidelity in Document Conversions
You convert a DOCX to Markdown. You get a file back.
But did the headings survive? Did the table relationships hold? Did the meaning of the content actually make it across?
You have no idea. Neither does any tool on the market.
That's the problem I set out to solve.
The Gap Nobody Filled
I surveyed 7+ industry-standard document conversion tools — CloudConvert, Zamzar, Adobe, Pandoc, and others. Every single one gives you a converted file and nothing else. No quality score. No warning if 30% of your content got mangled. No way to know if that legal brief you just converted lost a critical table.
I searched arXiv, ACM Digital Library, and IEEE Xplore for terms like "cross-format semantic preservation" and "document conversion quality metric."
Zero results.
A Dagstuhl Seminar in 2010 noted that "very few tools available for measuring specific properties of document conversion" existed. That was 2010.
In 2026, the gap was still there. Untouched.
The Semantic Fidelity Index (SFI)
I designed a metric called the Semantic Fidelity Index (SFI) — a weighted composite score that measures how much meaning survives a document format conversion.
Three dimensions:
| Dimension | Weight | What it measures |
|---|---|---|
| S_structural | 35% | Headings, tables, lists — did the skeleton survive? |
| S_semantic | 45% | Meaning of content via embedding similarity |
| S_functional | 20% | Links, metadata, formulas — did the working parts survive? |
Semantic meaning gets the highest weight because it's the hardest to get back once it's gone. You can re-add a heading. You can't re-add meaning you didn't know was missing.
The Grade Scale
| Grade | SFI | What it means |
|---|---|---|
| A | ≥ 0.85 | Excellent — minimal loss |
| B | 0.70 – 0.84 | Good — minor loss |
| C | 0.55 – 0.69 | Fair — review recommended |
| D | 0.40 – 0.54 | Poor — significant loss |
| F | < 0.40 | Very poor — critical content missing |
How It Works Under the Hood
The backend is a Python FastAPI microservice using all-MiniLM-L6-v2 (sentence-transformers) for semantic scoring.
For each conversion pair, it:
- 1.Extracts text + structural elements from both source and target (format-aware parsers for DOCX, PDF, HTML, Markdown, TXT)
- 2.Scores structural fidelity — cross-format aware, so PDF and TXT targets aren't penalised for not having
<h1>tags (they can't, by design) - 3.Scores semantic fidelity — chunks both documents, computes cosine similarity per chunk pair with
all-MiniLM-L6-v2 - 4.Scores functional fidelity — link counts, metadata presence, formula retention
- 5.Combines into a single SFI score with the weighted formula
The frontend is Next.js 14 with a pure SVG radar chart (no external charting library) — three axes for Structural, Semantic, Functional — with grade-colored fills and automatic warning banners for C/D/F grades.
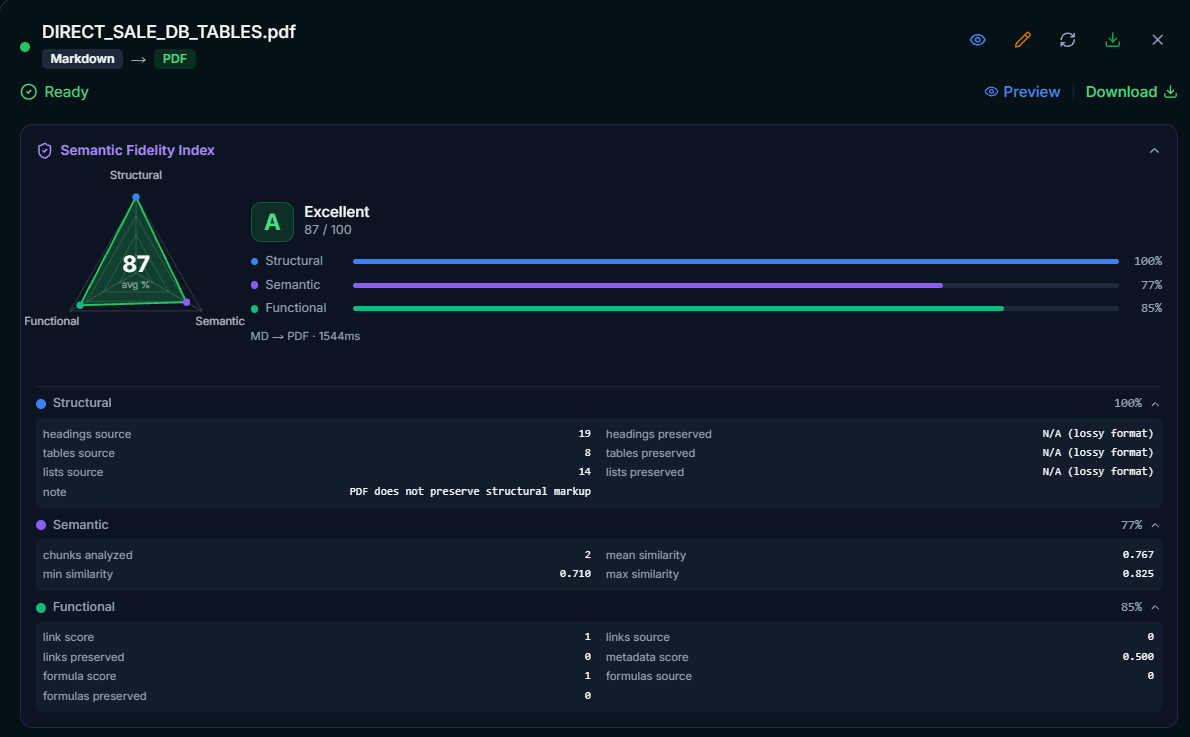
Here's the SFI dashboard scoring a real MD → PDF conversion — grade A, 87/100:
!SFI Dashboard — MD to PDF conversion, Grade A 87/100
The Round-Trip Test
One of the most interesting features I built is round-trip chain scoring.
Convert MD → DOCX → MD and score both steps. If step 1 scores 81% and step 2 scores 70%, the round-trip retained 70/81 = 86% of fidelity — meaning 14% was permanently lost in the round trip.
This is something no tool in the market currently shows you.
Here's a live example — HTML → DOCX → HTML, both steps graded B at 75%, with 100% round-trip retention:
!SFI Round-Trip Score — HTML to DOCX, Grade B 75/100
{kind=link}
ConvertBench: A Benchmark Dataset
To validate SFI, I built ConvertBench v1 — 13 source documents across 5 content archetypes specifically designed to stress-test different SFI dimensions:
- API documentation (tables, code blocks, links)
- Academic writing (dense prose, citations)
- Business reports (data tables)
- Code-heavy tutorials (code fences)
- Plain prose essays (pure semantic signal)
Results across 84 conversion pairs:
| Pair | Mean SFI | Grade |
|---|---|---|
| pdf→txt | 1.0000 | A |
| docx→html | 0.9834 | A |
| md→docx | 0.7291 | B |
| html→docx | 0.6690 | C |
| Overall | 0.8844 | A |
Key finding: html→docx is the weakest conversion pair. HTML's flexible structure doesn't map cleanly to DOCX's rigid style system — and now, for the first time, there's a number that proves it.
What I Learned Building This
The hardest part wasn't the ML. It was cross-format awareness. Early versions penalised PDF and TXT outputs for missing heading markup — which is unfair, because those formats can't preserve it. Teaching the metric to understand format constraints was the real research challenge.
The most surprising result: pdf→txt scores a perfect 1.0. When a PDF is pure text with no tables or links, conversion to TXT is lossless. Obvious in hindsight. Not obvious until you measure it.
Bugs that taught me things:
- A source filename without the right extension caused the Python backend to misdetect the format — fixed by rewriting extensions to match
fromFormatbefore sending para.stylecan beNonein DOCX files from some converters — a crash waiting to happen in productionpdf-parsenpm package breaks in Next.js serverless — moved all PDF extraction to Python withpdfminer.six
Try It
FileFlowOne is live and open source.
Live app: fileflow-one.kavishkadinajara.com GitHub: github.com/kavishkadinajara/fileflow-one
Upload any document, convert it, and see your SFI score automatically — no button click needed.
What's Next
This is Gap 1 of a larger research agenda around edge-based SLM optimization for document processing. The SFI lays the measurement foundation — you can't improve what you can't measure.
Planned next steps:
- Expand ConvertBench to 500+ documents
- Non-English document evaluation
- Image-bearing document scoring (visual content is currently outside SFI's scope)
- PPTX format support
If you work on document processing, NLP, or information retrieval and this problem space interests you — I'd genuinely love to connect.